主页 > imtoken钱包转usdt > 从''.length !== 1 理解js中的字符串编码
从''.length !== 1 理解js中的字符串编码
计算机基础
众所周知,计算机底层的所有数据都以010101的二进制形式存在
(一)现有基础
ps: Number.parseInt 解析一个字符串,返回一个指定基数的十进制整数
使用二进制,为什么是 8/10/16 基数
更好的是,你不能总是写一串 1010 就说是 10。二进制使用起来很不方便,16/10/8 基数可以解决这个问题。基数越大一千进制的单位一千进制的单位,数字的表达长度越短。
例如:十进制的 256 转换为二进制 parseInt(256).toString(2) === '100000000'
转换原理
二、八、十、十六进制转换(图解)
比如二进制→十六进制(取四合一法)11010111 ==> 7D
0111 = ( 0 * 2^3) + (12^2) + (12^1) + (1*2^0) = 7;
1101 = ( 1 * 2^3) + (12^2) + (02^1) + (1*2^0) = D(13) ;
(二)计算机中的存储单元(位)(三)常用字符编码
编码:从一种格式转换成另一种格式,可以考虑把0、1翻译成你认识的字符,比如英文、中文
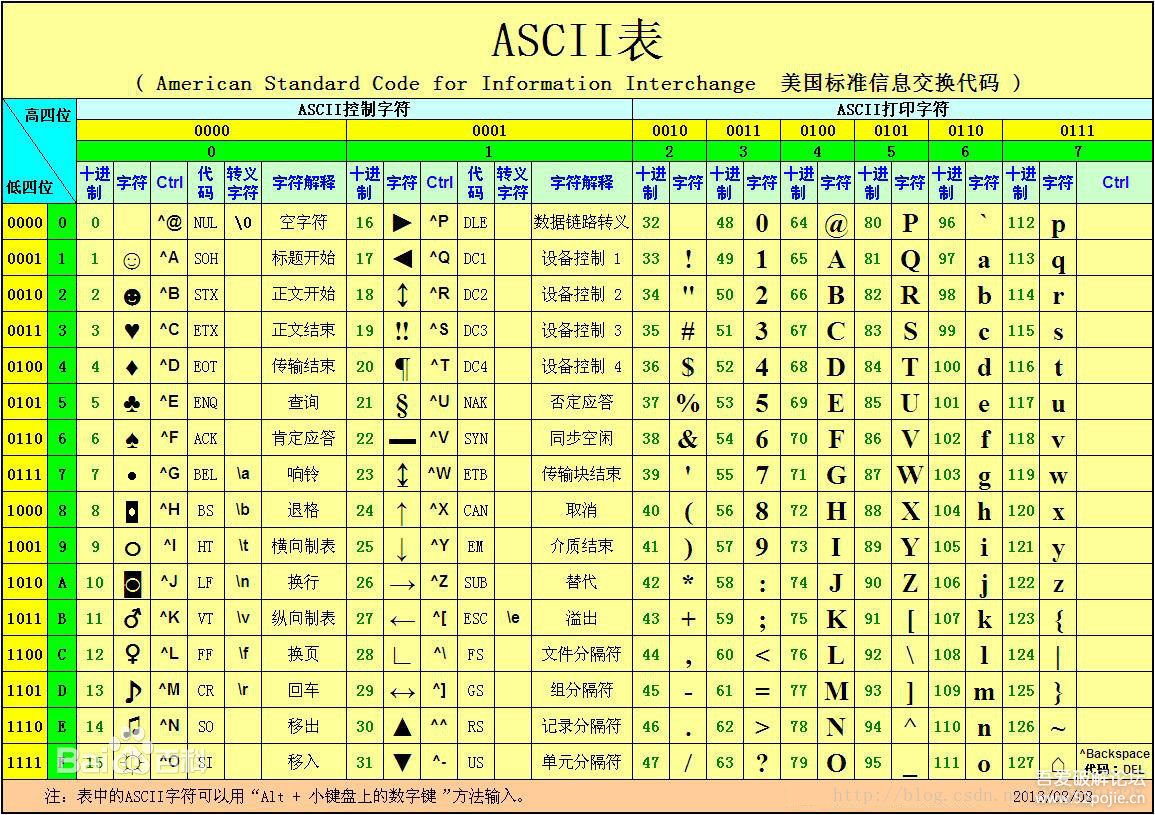
ASCII码
ASCII对照表
美国制定了一套字符编码,用单字节表示拉丁字母(英文字母)、阿拉伯数字(即1234567890)、标点符号(,.!等)、特殊符号(@#$%^&等)和一些字符与控制函数(回车、换行)和二进制位的关系,做了统一的映射,这叫做ASCII码,一直沿用至今。一共指定了128个字符,如空格SPACE为32(二进制00100000),大写A为65(二进制01000001)
ps:由于1字节是8位,所以应该最多支持2^8 = 256种情况。其实ASCII码的高位总是0.,所以支持2^7 = 128
标准的ASCII码是基本的128位,欧洲一些国家将ASCII码的后128位扩展为255位,称为扩展ASCII码。
统一码

汉字Unicode码位范围
为了解决乱码问题,Unicode将所有语言统一为一组编码,从0开始,给每个符号分配一个唯一的编号,称为“码点”。例如,代码点 0 的符号为空(意味着所有位都是 0)。
注意:Unicode 只是一个符号集,而不是一种编码。大多数中文都是两字节码位。它只规定了符号和二进制码的映射关系,并没有规定二进制码应该如何存储。
unicode的问题:
假设 Unicode 统一规定每个符号存储 2 个字节,如果 ASCII 编码的 A 用 Unicode 编码,只需要在前面加 0。因此,A的Unicode编码为00000000 01000001,存储空间翻倍,在存储和传输方面非常不经济
UTF-8

它是一种变长编码方式(减少存储和传输),是目前互联网上使用最广泛的Unicode实现。一个 Unicode 字符根据不同的数字大小编码为 1-4 个字节。常用英文字母编码为 1 个字节。常用的汉字通常是3个字节。对于单字节符号,字节的第一个字节被编码。一位设置为 0,接下来的 7 位是该符号的 unicode 码。所以对于英文字母,UTF-8编码和ASCII码是一样的
UTF-32
固定 4 个字节来表示一个字符
UTF-16
UTF-16 结合了固定长度和可变长度的编码方法。编码长度要么是2字节(U+0000到U+FFFF)要么是4字节(U+010000到U+10FFFF,英文编码为2字节,常用汉字一般为4字节
JS中字符串编码ES5的问题

只有 Unicode 码位小于 0xFFFF 的字符才能被正确识别,导致以下问题:
(1)length属性的值与肉眼看到的不符
(2)for循环使用16位编码作为单位而不是字符,子串切片repalce也有同样的问题
let text = String.fromCodePoint(0x20BB7)//''
text.length //2 => (1)字符串长度与肉眼所见不相符
for (let i = 0; i < text.length; i++) {
console.log(text[i]); // 输出两个 [0]'\uD842' [1]'\uDFB7' => (2)循环错误
}
//(3)其他处理函数错误
text.substring(0,1) // '\uD842'
text.substring(0,2) // ''
// slice,repalce等的字符串方法的反应也是一样的 都只对2字节的码点有效
复制代码ES6 的增强
原方法String.prototype.charCodeAt(index)返回0到65535(0xFFFF)的UTF-16编码,如果大于0xFFFF,返回第一个编码单元
let text = String.fromCodePoint(0x20BB7)//''
text.codePointAt(0) //134071
text.codePointAt(0).toString(16) // '20bb7' 大于2字节的unicode码点
Array.from(text).length //1 => (1)正确的长度
for (let str of text) {
console.log(str); // => (2)循环正确
}
// (3) 将码点放入大括号,就能正确解读该字符
// 之前的双字节
"\uD842\uDFB7"
"\u20BB7" // '₻7' 输出有误
// 现在
"\u{20BB7}"// ""
// (4) 正则增加了u修饰符,支持4字节码点
console.log(/^.$/.test(text)) //false
console.log(/^.$/u.test(text) )// true
// (5) 带附加符号的表示
// 方法一(单个字符)
'\u01D1' // 'Ǒ'
// 方法二
'\u004F\u030C' // 'Ǒ'
// (6) 用 normalize方法修正
'\u01D1'==='\u004F\u030C' //false
'\u01D1'.normalize() === '\u004F\u030C'.normalize()
// true
复制代码如果您有任何问题,请纠正我
参考